6 Continuous Probability Distributions
Chapter 5 dealt with probability distributions arising from discrete random variables. Mostly that chapter focused on the binomial experiment. There are many other experiments from discrete random variables that exist but are not covered in this book.
Chapter 6 deals with probability distributions that arise from continuous ran- dom variables. The focus of this chapter is a distribution known as the normal distribution, though realize that there are many other distributions that exist. A few others are examined in future chapters.
Looking at the density plot of a quantitative variable, one can guess what the distribution of that variable is. As an example, consider the NHANES data frame. One variable to consider is Weight. The density plot of Weight is
(Figure 6.2looks somewhat symmetric, and maybe bell shaped.
Consider, the variable head circumference (HeadCirc) in the NHANES data frame. The density plot for this variable is
(ref:headcirc6-density=cap) Density Plot of Head Circumference of a Person This (Figure ??) looks somewhat skewed left.
Now consider the variable BMI from the NHANES data frame. The density plot is
This density plot appears to be skewed left.
Now consider the variable SmokeAge. Its density plot is (Figure 6.4) This distribution appears to be bimodal.
177
0.015
density
0.010
0.005
0.000
050100150200
Weight
0.15
density
0.10
0.05
0.00
Figure 6.1: Density Plot of Weight of a Person
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
36394245
HeadCirc
Figure 6.2: (ref:headcirc6-density=cap)
0.06
0.04
density
0.02
0.00
20406080
BMI
density
0.10
0.05
0.00
Figure 6.3: Density Plot of BMI of a Person
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
204060
SmokeAge
Figure 6.4: Density Plot of Age when Person Started Smoking
lastly, consider the variable Pulse. The density plot is (Figure 6.5)
0.03
density
0.02
0.01
0.00
406080100120140
Pulse
Figure 6.5: Density Plot of Pulse Rate of a person
This density plot appears to be symmetric and could almost be considered bell shaped.
The reason that one considers the density plots to understand the distribution of the population, is that in some cases the distribution can be approximated with a known distribution that has certain properties. There are many known distribution. Some examples are the Uniform distribution, the Chi-Squared distribution, the Student’s T distribution, and the normal distribution. The normal distribution is one of the more common distributions to use as a model, and it will be explored in this chapter. But do realize that there are many other distributions that one can use.
** Normal Distribution **
𝜇 = 2
𝜇
Many populations have a distribution that is a symmetric, unimodal, and bell- shaped. For example: height, blood pressure, and cholesterol level. However, not every bell shaped curve is a normal curve. In a normal curve, there is a specific relationship between its “height” and its “width.” Normal curves can be tall and skinny or they can be short and fat. They are all symmetric, unimodal, and centered at , the population mean. (Figure 6.6) and (Figure 6.7) show two different normal curves drawn on the same scale. Both havebut the one in (Figure 6.6) has a standard deviation of 1 and the one in (Figure 6.7)
0.0
0.1
0.2
dnorm(x, 2, 1)
0.3
0.4
has a standard deviation of 4. Notice that the larger standard deviation makes the graph wider (more spread out) and shorter.
−10−50510
x
Figure 6.6: Normal Distribution with 𝜇 = 2, and 𝜎 = 1
Every normal curve has common features.
𝜇
The center, or the highest point, is at the population mean, .- The transition points are the places where the curve changes from a “hill” to a “valley”. The distance from the mean to the transition point is one standard deviation.
- The area under the whole curve is exactly 1. Therefore, the area under the half below or above the mean is 0.5.
𝑃(𝑎 ≤ 𝑥 ≤ 𝑏) = 𝑃(𝑎 < 𝑥 < 𝑏)
Just as in a discrete probability distribution, the object is to find the probability of an event occurring. However, unlike in a discrete probability distribution where the event can be a single value, in a continuous probability distribution the event must be a range. You are interested in finding the probability of x occurring in the range between a and b, or. Calculus tells us this probability is the area under the curve in the interval from a to b.
Before looking at the process for finding the probabilities under the normal curve, it is somewhat useful to look at the Empirical Rule that gives approx-
0.3
0.4
dnorm(x, 2, 4)
0.0
0.1
0.2
−10−50510
x
Figure 6.7: Normal Distribution with 𝜇 = 2, and 𝜎 = 4
imate values for these areas. The Empirical Rule is just an approximation and it will only be used in this section to give you an idea of what the size of the probabilities is for different shadings. A more precise method for finding prob- abilities for the normal curve will be demonstrated in the next section. Please do not use the empirical rule except for real rough estimates.
The Empirical Rule for any normal distribution: Approximately 68% of the data is within one standard deviation of the mean. Approximately 95% of the data is within two standard deviations of the mean. Approximately 99.7% of the data is within three standard deviations of the mean.
Image #6.1: Empirical Rule
Be careful, there is still some area left over in each end. Remember, the maxi- mum a probability can be is 100%, so if you calculate you will see that for both ends together there is 0.3% of the curve. Because of symmetry, you can divide this equally between both ends and find that there is 0.15% in each tail beyond the 3rd standard deviations.
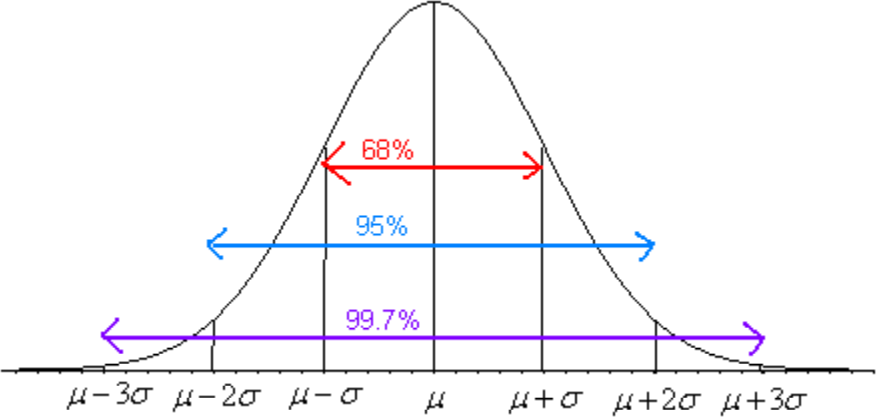
Figure 6.8: Graph of Empirical Rule
Finding Probabilities for the Normal Distri- bution
The Empirical Rule is just an approximation and only works for certain values. What if you want to find the probability for x values that are not integer multi- ples of the standard deviation? The probability is the area under the curve. To find areas under the curve, you need calculus. Before technology, you needed to convert every x value to a standardized number, called the z-score or z-value or simply just z. The z-score is a measure of how many standard deviations an x value is from the mean. To convert from a normally distributed x value to a z-score, you use the following formula.
𝜎
z-score = 𝑥−𝜇
𝜇𝜎
where = mean of the population of the x value and = standard deviation for the population of the x value
The z-score is normally distributed, with a mean of 0 and a standard deviation of 1. It is known as the standard normal curve. The z-score is a measure of how many standard deviations a data value is from its mean. If the z-score is positive, the data value is above the mean. If the z-score is negative, the data value is below the mean. The farther the z-value is from 0, the farther the data value is from the mean.
These days technology can find probabilities without converting to the z-score and looking the probabilities up in a table. There are many programs available that will calculate the probability for a normal curve. The command on R to find the area to the left ie 𝑃 (𝑥 < 𝑣𝑎𝑙𝑢𝑒) is
0.00
0.01
pnorm(value, mean, standard deviation, lower.tail=TRUE)
The command on R to find the area to the right ie 𝑃 (𝑥 > 𝑣𝑎𝑙𝑢𝑒) is
pnorm(value, mean, standard deviation, lower.tail=FALSE)
Example: General Normal Distribution
The length of a human pregnancy is normally distributed with a mean of 272 days with a standard deviation of 9 days (Bhat & Kushtagi, 2006).
- State the random variable.
Solution:
x = length of a human pregnancy
- Find the probability of a pregnancy lasting more than 280 days.
Solution:
First translate the statement into a mathematical statement. 𝑃 (𝑥 > 280)
Now, draw a picture (Figure 6.9).
dnorm(x, 272, 9)
0.02
0.03
0.04
Pregnancy Length
240260280300320
x
Figure 6.9: Normal Distribution for 𝑃 (𝑥 > 280)
The probability of a pregnancy lasting longer than 280 days is 𝑃(𝑥 > 280) =
0.187. The command in R Studio is
0.00
0.01
pnorm(280, 272, 9, lower.tail=FALSE)
## [1] 0.1870314
Thus 18.7% of all pregnancies last more than 280 days. This is not unusual since the probability is greater than 5%.
- Find the probability of a pregnancy lasting less than 250 days.
Solution:
First translate the statement into a mathematical statement. 𝑃 (𝑥 < 250)
Now, draw a picture (Figure 6.10).
dnorm(x, 272, 9)
0.02
0.03
0.04
Pregnancy Length

240260280300320
x
Figure 6.10: Normal Distribution for 𝑃 (𝑥 < 250)
The probability of a pregnancy lasting longer than 250 days is 𝑃(𝑥 < 250) = 0.0073. The command in R Studio is
pnorm(250, 272, 9, lower.tail=TRUE)
## [1] 0.007253771
Thus 0.73% of all pregnancies last less than 250 days. This is unusual since the probability is less than 5%.
- Find the probability that a pregnancy lasts between 265 and 280 days.
0.00
0.01
Solution:
First translate the statement into a mathematical statement. 𝑃(265 < 𝑥 < 280)
Now draw a picture (Figure 6.11).
dnorm(x, 272, 9)
0.02
0.03
0.04
Pregnancy Length

240260280300320
x
Figure 6.11: Normal Distribution for 𝑃(265 < 𝑥 < 280)
𝑥 < 280) = 0.187
𝑃 (265 <
The probability of a pregnancy lasting between 265 days and 280 days is
. To find the area between two values on the normal distri- bution, first, find the area to the left of the lower value, Graphically, this looks like (Figure 6.12)
Now find the area less than 280. Graphically this looks like (Figure 6.13)
Looking at the three figures, if you take the area in (Figure 6.13) and subtract the area in (Figure 6.12), you get the area in the (Figure 6.11). In R Studio, the way to find the probability the probability of a pregnancy lasting between 265 days and 280 days, 𝑃 (265 < 𝑥 < 280) = 0.595 use the following command
pnorm(280, 272, 9, lower.tail=TRUE)–pnorm(265, 272, 9, lower.tail=TRUE)
## [1] 0.5946186
Thus 59.5% of all pregnancies last between 265 and 280 days.
- Find the length of pregnancy that 10% of all pregnancies last less than.
Solution:
0.00
0.01
0.00
0.01
dnorm(x, 272, 9)
0.02
0.03
0.04
Pregnancy Length
240260280300320
x
Figure 6.12: Normal Distribution for 𝑃 (𝑥 < 265)
dnorm(x, 272, 9)
0.02
0.03
0.04
Pregnancy Length
240260280300320
x
Figure 6.13: Normal Distribution for 𝑃 (𝑥 < 280)
This problem is asking you to find an x value from a probability. You want to find the x value that has 10% of the length of pregnancies to the left of it. In this case, you are given the probability. In R, the command is
qnorm(area, mean, standard deviation, lower.tail=TRUE or FALSE)
For this example since you know the area in the lower tail, then use lower.tail=TRUE. So the command is
qnorm(0.1, 272, 9, lower.tail = TRUE)
## [1] 260.466
Thus 10% of all pregnancies last less than approximately 260 days.
- Suppose you meet a woman who says that she was pregnant for less than 250 days. Would this be unusual and what might you think?
Solution:
From part (c) you found the probability that a pregnancy lasts less than 250 days is 0.73%. Since this is less than 5%, it is very unusual. You would think that either the woman had a premature baby, or that she may be wrong about when she actually became pregnant.
Example: General Normal Distribution
The mean mathematics SAT score in 2012 was 514 with a standard deviation of 117 (”Total group profile,” 2012). Assume the mathematics SAT score is normally distributed.
- State the random variable.
Solution:
x = mathematics SAT score
- Find the probability that a person has a mathematics SAT score over 700.
Solution:
First translate the statement into a mathematical statement. P(x>700) Now, draw a picture (Figure 6.14).
To find 𝑃 (𝑥 > 700) = 0.0559, the command in R would be
pnorm(700, 514,117, lower.tail = FALSE)
## [1] 0.05594631
There is a 5.6% chance that a person scored above a 700 on the mathematics SAT test. This is not unusual.
dnorm(x, 514, 117)
0.00000.00100.00200.0030
SAT Mathematics Score

2004006008001000
x
Figure 6.14: Normal Distribution for SAT Mathematics Score
- Find the probability that a person has a mathematics SAT score of less than 400.
Solution:
First translate the statement into a mathematical statement. 𝑃 (𝑥 < 400)
Now, draw a picture (Figure 6.15).
To find 𝑃 (𝑥 < 400) = 0.165, the command in R would be
pnorm(400, 514, 117, lower.tail = TRUE)
## [1] 0.1649392
So, there is a 16.5% chance that a person scores less than a 400 on the mathe- matics part of the SAT.
- Find the probability that a person has a mathematics SAT score between a 500 and a 650.
Solution:
First translate the statement into a mathematical statement 𝑃(500 < 𝑥 < 650)
Now, draw a picture (Figure 6.16).
To find 𝑃 (500 < 𝑥 < 650) = 0.425, the command in R would be
dnorm(x, 514, 117)
0.00000.00100.00200.0030
SAT Mathematics Score
2004006008001000
x
Figure 6.15: Normal Distribution for Mathematics SAT Score
dnorm(x, 514, 117)
0.00000.00100.00200.0030
SAT Mathematics Score

2004006008001000
x
Figure 6.16: Normal Distribution for SAT Mathematics Score
pnorm(650, 514, 117, lower.tail = TRUE)–pnorm(500, 514, 117, lower.tail=TRUE)
## [1] 0.4250851
So, there is a 42.5% chance that a person has a mathematical SAT score between 500 and 650.
- Find the mathematics SAT score that represents the top 1% of all scores.
Solution:
This problem is asking you to find an x value from a probability. You want to find the x value that has 1% of the mathematics SAT scores to the right of it. In this case you are using the upper tail of the curve. To find this x value on R Studio, use the command
qnorm(0.01, 514, 117, lower.tail=FALSE)
## [1] 786.1827
So, 1% of all people who took the SAT scored over about 786 points on the mathematics SAT.
Homework
Find each of the probabilities, where z is a z-score from the standard normal distribution with mean ofand standard deviation. It helps to draw a picture for each problem.
a.) 𝑃 (𝑧 < 2.36) b.) 𝑃 (𝑧 > 0.67) c.) 𝑃(0 < 𝑥 < 2.11) d.) 𝑃 (−2.78 < 𝑧 < 1.97)
- Find the z-score corresponding to the given area. Remember, z is dis- tributed as the standard normal distribution with mean of 𝜇 = 0 and standard deviation 𝜎 = 1.
- The area to the left of z is 15%.
- The area to the right of z is 65%.
- The area to the left of z is 10%.
- The area to the right of z is 5%.
- The area between −𝑧 and z is 95%. (Hint draw a picture and figure out the area to the left of −𝑧.)
- The area between −𝑧 and z is 99%.
- If a random variable that is normally distributed has a mean of 25 and a standard deviation of 3, convert the given value to a z-score.
- x = 23
- x = 33
- x = 19
- x = 45
- According to the WHO MONICA Project the mean blood pressure for people in China is 128 mmHg with a standard deviation of 23 mmHg (Kuulasmaa, Hense & Tolonen, 1998). Assume that blood pressure is normally distributed.
- State the random variable.
- Find the probability that a person in China has blood pressure of 135 mmHg or more.
- Find the probability that a person in China has blood pressure of 141 mmHg or less.
- Find the probability that a person in China has blood pressure between 120 and 125 mmHg.
- Is it unusual for a person in China to have a blood pressure of 135 mmHg? Why or why not?
- What blood pressure do 90% of all people in China have less than?
- The size of fish is very important to commercial fishing. A study conducted in 2012 found the length of Atlantic cod caught in nets in Karlskrona to have a mean of 49.9 cm and a standard deviation of 3.74 cm (Ovegard, Berndt & Lunneryd, 2012). Assume the length of fish is normally dis- tributed.
- State the random variable.
- Find the probability that an Atlantic cod has a length less than 52 cm.
- Find the probability that an Atlantic cod has a length of more than 74 cm.
- Find the probability that an Atlantic cod has a length between 40.5 and
57.5 cm.
- If you found an Atlantic cod to have a length of more than 74 cm, what could you conclude?
- What length are 15% of all Atlantic cod longer than?
- The mean cholesterol levels of women age 45-59 in Ghana, Nigeria, and Seychelles is 5.1 mmol/l and the standard deviation is 1.0 mmol/l (Lawes, Hoorn, Law & Rodgers, 2004). Assume that cholesterol levels are normally distributed.
- State the random variable.
- Find the probability that a woman age 45-59 in Ghana, Nigeria, or Sey- chelles has a cholesterol level above 6.2 mmol/l (considered a high level).
- Find the probability that a woman age 45-59 in Ghana, Nigeria, or Sey- chelles has a cholesterol level below 5.2 mmol/l (considered a normal level).
- Find the probability that a woman age 45-59 in Ghana, Nigeria, or Sey- chelles has a cholesterol level between 5.2 and 6.2 mmol/l (considered borderline high).
- If you found a woman age 45-59 in Ghana, Nigeria, or Seychelles having a cholesterol level above 6.2 mmol/l, what could you conclude?
- What value do 5% of all woman ages 45-59 in Ghana, Nigeria, or Seychelles
have a cholesterol level less than?
- In the United States, males between the ages of 40 and 49 eat on average
103.1 g of fat every day with a standard deviation of 4.32 g (”What we eat,” 2012). Assume that the amount of fat a person eats is normally distributed.
- State the random variable.
- Find the probability that a man age 40-49 in the U.S. eats more than 110 g of fat every day.
- Find the probability that a man age 40-49 in the U.S. eats less than 93 g of fat every day.
- Find the probability that a man age 40-49 in the U.S. eats less than 65 g of fat every day.
- If you found a man age 40-49 in the U.S. who says he eats less than 65 g of fat every day, would you believe him? Why or why not?
- What daily fat level do 5% of all men age 40-49 in the U.S. eat more than?
- A dishwasher has a mean life of 12 years with an estimated standard deviation of 1.25 years (”Appliance life expectancy,” 2013). Assume the life of a dishwasher is normally distributed.
- State the random variable.
- Find the probability that a dishwasher will last more than 15 years.
- Find the probability that a dishwasher will last less than 6 years.
- Find the probability that a dishwasher will last between 8 and 10 years.
- If you found a dishwasher that lasted less than 6 years, would you think that you have a problem with the manufacturing process? Why or why not?
- A manufacturer of dishwashers only wants to replace free of charge 5% of all dishwashers. How long should the manufacturer make the warranty period?
- The mean starting salary for nurses is $67,694 nationally (”Staff nurse -,” 2013). The standard deviation is approximately $10,333. Assume that the starting salary is normally distributed.
- State the random variable.
- Find the probability that a starting nurse will make more than $80,000.
- Find the probability that a starting nurse will make less than $60,000.
- Find the probability that a starting nurse will make between $55,000 and
$72,000.
- If a nurse made less than $50,000, would you think the nurse was under paid? Why or why not?
- What salary do 30% of all nurses make more than?
- The mean yearly rainfall in Sydney, Australia, is about 137 mm and the standard deviation is about 69 mm (”Annual maximums of, ”2013). As- sume rainfall is normally distributed.
- State the random variable.
- Find the probability that the yearly rainfall is less than 100 mm.
- Find the probability that the yearly rainfall is more than 240 mm.
- Find the probability that the yearly rainfall is between 140 and 250 mm.
- If a year has a rainfall less than 100mm, does that mean it is an unusually dry year? Why or why not?
- What rainfall amount are 90% of all yearly rainfalls more than?
Assessing Normality
The distributions you have seen up to this point have been assumed to be normally distributed, but how do you determine if it is normally distributed. One way is to take a sample and look at the sample to determine if it appears normal. If the sample looks normal, then most likely the population is also. Here are some guidelines that are use to help make that determination.
- Density Plot: Make a density plot. For a normal distribution, the den- sity plot should be roughly bell-shaped. For small samples, this is not very accurate, and another method is needed. A distribution may not look normally distributed from the density plot, but it still may be nor- mally distributed.
- Normal quantile plot (or normal probability plot): This plot is provided through statistical software on a computer. If the points lie close to a line, the data comes from a distribution that is approximately normally distributed. If the points do not lie close to a line or they show a pattern that is not a line, the data are likely to come from a distribution that is not normally distributed.
To create a density plot on R Studio:
Read the Data Frame into R Studio. The command for density is
gf_density(~variable, data=Data Frame)
See section 2.2 for more examples of this.
To create a normal quantile plot on R Studio:
Read the Data Frame into R Studio. The command for normal quantile plot is
gf_qqnorm(~variable, data=Data Frame)
Realize that your random variable may be normally distributed, even if the sample fails the two tests. However, if the density plot definitely doesn’t look symmetric and bell shaped, and the normal probability plot doesn’t look lin-
ear, then you can be fairly confident that the data set does not come from a population that is normally distributed.
Example: Is It Normal?
In Kiama, NSW, Australia, there is a blowhole. The data in table #6.2.1 are times in seconds between eruptions (”Kiama blowhole eruptions,” 2013). Do the data come from a population that is normally distributed?
Table #6.2.1: Time (in Seconds) Between Kiama Blowhole Eruptions
Eruption<-read.csv( “https://krkozak.github.io/MAT160/Blowhole_eruptions.csv”)head(Eruption)
##Interval
|
## 1 |
83 |
|
## 2 |
51 |
|
## 3 |
87 |
|
## 4 |
60 |
|
## 5 |
28 |
|
## 6 |
95 |
Code book for Data Frame Eruption
Description The ocean swell produces spectacular eruptions of water through a hole in the cliff at Kiama, about 120km south of Sydney, known as the Blowhole. The times at which 65 successive eruptions occurred from 1340 hours on 12 July 1998 were observed using a digital watch.
Format This data frame contains the following columns: Interval: Waiting time between eruptions (seconds)
Source Kiama Blowhole Eruptions. (n.d.). Retrieved from http://www.statsci. org/data/oz/kiama.html
References The data was collected and contributed by Jim Irish, Faculty of Engineering, University of Technology, Sydney.
- State the random variable
Solution:
x = time in seconds between eruptions of Kiama Blowhole
- Draw a Density plot
Solution:
The density plot produced is in (Figure 6.17).
gf_density(~Interval, data=Eruption, title=”Eruption times for Kiama Blowhole”)
Eruption times for Kiama Blowhole
0.015
density
0.010
0.005
0.000
050100150
Interval
Figure 6.17: Density Plot for Kiama Blowhole This looks skewed right and not symmetric.
- Draw the normal quantile plot.
Solution:
The normal quantile plot is in (Figure 6.18).
gf_qq(~Interval, data=Eruption, title=”Eruption times for Kiama Blowhole”)
(Figure 6.18) looks more like an exponential growth than linear.
e. Do the data come from a population that is normally distributed?
Solution:
Considering the density plot is skewed right, and the normal probability plot does not look linear, then the conclusion is that this sample is not from a population that is normally distributed.
Example: Is It Normal?
The US National Center for Health Statistics (NCHS) conducted a series of health and nutrition surveys called NHANES. One of the many variables in
Eruption times for Kiama Blowhole

150
sample
100
50
0
−2−1012
theoretical
Figure 6.18: Normal Probability Plot
NHANES is pulse. Determine if pulse is a normally distributed variable.
Table #6.2.2: NHANES
## # A tibble: 6 x 76
##151624 2009_10 male34 ” 30-39″409White##251624 2009_10 male34 ” 30-39″409White##351624 2009_10 male34 ” 30-39″409White##451625 2009_10 male4 ” 0-9″49Other##551630 2009_10 female49 ” 40-49″596White##651638 2009_10 male9 ” 0-9″115White
##ID SurveyYr GenderAge AgeDecade AgeMonths Race1 ##<int> <fct><fct> <int> <fct><int> <fct>
## # … with 69 more variables: Race3 <fct>, Education <fct>, ## # MaritalStatus <fct>, HHIncome <fct>, HHIncomeMid <int>, ## # Poverty <dbl>, HomeRooms <int>, HomeOwn <fct>,
## # Work <fct>, Weight <dbl>, Length <dbl>, HeadCirc <dbl>, ## # Height <dbl>, BMI <dbl>, BMICatUnder20yrs <fct>,
## #BMI_WHO <fct>, Pulse <int>, BPSysAve <int>, ## #BPDiaAve <int>, BPSys1 <int>, BPDia1 <int>,
## #BPSys2 <int>, BPDia2 <int>, BPSys3 <int>, BPDia3 <int>, ## #Testosterone <dbl>, DirectChol <dbl>, TotChol <dbl>, ## #UrineVol1 <int>, UrineFlow1 <dbl>, UrineVol2 <int>,
|
## |
# |
UrineFlow2 <dbl>, Diabetes <fct>, DiabetesAge <int>, |
|
## |
# |
HealthGen <fct>, DaysPhysHlthBad <int>, |
|
## |
# |
DaysMentHlthBad <int>, LittleInterest <fct>, |
|
## |
# |
Depressed <fct>, nPregnancies <int>, nBabies <int>, |
|
## |
# |
Age1stBaby <int>, SleepHrsNight <int>, |
|
## |
# |
SleepTrouble <fct>, PhysActive <fct>, |
|
## |
# |
PhysActiveDays <int>, TVHrsDay <fct>, CompHrsDay <fct>, |
|
## |
# |
TVHrsDayChild <int>, CompHrsDayChild <int>, |
|
## |
# |
Alcohol12PlusYr <fct>, AlcoholDay <int>, |
|
## |
# |
AlcoholYear <int>, SmokeNow <fct>, Smoke100 <fct>, |
|
## |
# |
Smoke100n <fct>, SmokeAge <int>, Marijuana <fct>, |
|
## |
# |
AgeFirstMarij <int>, RegularMarij <fct>, |
|
## |
# |
AgeRegMarij <int>, HardDrugs <fct>, SexEver <fct>, |
|
## |
# |
SexAge <int>, SexNumPartnLife <int>, |
|
## |
# |
SexNumPartYear <int>, SameSex <fct>, |
|
## |
# |
SexOrientation <fct>, PregnantNow <fct> |
- State the random variable
Solution:
x = pulse
- Draw a density plot
Solution:
The density plot is in (Figure 6.19).
gf_density(~Pulse, data=NHANES, title=”Pulse Rate”)
This looks somewhat symmetric.
- Draw the normal quantile plot.
Solution:
The normal quantile plot is in (Figure 6.20).
gf_qq(~Pulse, data=NHANES, title=”Pulse Rate”)
(Figure 6.20) looks fairly linear.
e. Do the data come from a population that is normally distributed?
Solution:
Considering the density plot is bell shaped and the normal probability plot looks linear. The conclusion is that this sample is from a population that is normally distributed.
Pulse Rate
0.03
density
0.02
0.01
0.00
406080100120140
Pulse
Figure 6.19: Density Plot for Pulse
Pulse Rate

140
120
100
sample
80
60
40
−4−2024
theoretical
Figure 6.20: Normal Quantile Plot
Homework
- Cholesterol data was collected on patients four days after having a heart attack. The data is in table #6.2.3. Assess if the data is from a population that is normally distributed.
Table #6.2.3: Cholesterol Data Collected Four Days After a Heart Attack
Cholesterol<-read.csv( “https://krkozak.github.io/MAT160/cholesterol.csv”)head(Cholesterol)
|
## |
patient |
day2 |
day4 |
day14 |
|
|
## |
1 |
1 |
270 |
218 |
156 |
|
## |
2 |
2 |
236 |
234 |
NA |
|
## |
3 |
3 |
210 |
214 |
242 |
|
## |
4 |
4 |
142 |
116 |
NA |
|
## |
5 |
5 |
280 |
200 |
NA |
|
## |
6 |
6 |
272 |
276 |
256 |
Code Book for Cholesterol See problem 3.1.1 in Section 3.1 homework.
- The size of fish is very important to commercial fishing. A study conducted in 2012 collected the lengths of Atlantic cod caught in nets in Karlskrona (Ovegard, Berndt & Lunneryd, 2012). Data based on information from the study is in table #6.2.4. Determine if the data is from a population that is normally distributed.
Table #6.2.4: Atlantic Cod Lengths
Cod<-read.csv( “https://krkozak.github.io/MAT160/cod.csv”)head(Cod)
|
## |
length |
|
|
## |
1 |
48 |
|
## |
2 |
50 |
|
## |
3 |
50 |
|
## |
4 |
55 |
|
## |
5 |
53 |
|
## |
6 |
50 |
- The WHO MONICA Project collected blood pressure data for people in China (Kuulasmaa, Hense & Tolonen, 1998). Data based on information from the study is in table #6.2.5. Determine if the data is from a popula- tion that is normally distributed.
Table #6.2.5: Blood Pressure Values for People in China
BP<-read.csv( “https://krkozak.github.io/MAT160/bp.csv”)head(BP)
##pressure
|
## 1 |
114 |
|
## 2 |
141 |
|
## 3 |
154 |
|
## 4 |
137 |
|
## 5 |
131 |
|
## 6 |
132 |
- Annual rainfalls for Sydney, Australia are given in table #6.2.6. (”Annual maximums of,” 2013). Can you assume rainfall is normally distributed?
Table #6.2.6: Annual Rainfall in Sydney, Australia
Annual<-read.csv( “https://krkozak.github.io/MAT160/annual.csv”)head(Annual)
##amount ## 1 146.8
## 2 383.0
## 390.9
## 4 178.1
## 5 267.5
## 695.5
SamplingDistributionandtheCentral Limit Theorem
You now have most of the skills to start statistical inference, but you need one more concept.
First, it would be helpful to state what statistical inference is in more accurate terms.
Statistical Inference: to make accurate decisions about parameters from statistics
When it says “accurate decision,” you want to be able to measure how accurate. You measure how accurate using probability. In both binomial and normal distributions, you needed to know that the random variable followed either distribution. You need to know how the statistic is distributed and then you
can find probabilities. In other words, you need to know the shape of the sample mean or whatever statistic you want to make a decision about.
How is the statistic distributed? This is answered with a sampling distribution.
Sampling Distribution: how a sample statistic is distributed when repeated trials of size n are taken.
Example: Sampling Distribution
The NHANES data frame has the pulse rates for approximately 50,000 individ- uals. The random variable is x = pulse rate. The probability distribution of this random variable is presented in (Figure 6.21. Although pulse rates from 50,000 individuals isn’t the entire population, the sample is most likely a good representation of the population. Thus, it is safe to assume the population is normally distributed. An estimate for the population mean is 73.6 pbm, and the population standard deviation estimate is 12.2 bpm.
0.03
density
0.02
0.01
0.00
406080100120140
Pulse
Figure 6.21: Distribution of Pulse Rate
##mean_Pulse sd_Pulse ## 173.55973 12.15542
Suppose you take a random sample of 10 pulse rates from those 50,000 individ- uals. A random sample of data from 10 individuals is:
NHANES%>%sample_n(size=10)
|
## |
# A tibble: 10 x 76 |
|
|||||||
|
## |
ID SurveyYr Gender |
Age |
AgeDecade |
AgeMonths |
Race1 |
||||
|
## |
<int> <fct><fct> |
<int> |
<fct> |
<int> |
<fct> |
||||
|
## |
1 |
62575 |
2011_12 |
female |
24 |
“ |
20-29″ |
NA |
White |
|
## |
2 |
69138 |
2011_12 |
female |
16 |
“ |
10-19″ |
NA |
White |
|
## |
3 |
71611 |
2011_12 |
female |
15 |
“ |
10-19″ |
NA |
White |
|
## |
4 |
58941 |
2009_10 |
male |
8 |
“ |
0-9″ |
104 |
Mexi~ |
|
## |
5 |
67166 |
2011_12 |
female |
9 |
“ |
0-9″ |
NA |
Hisp~ |
|
## |
6 |
63979 |
2011_12 |
male |
8 |
“ |
0-9″ |
NA |
White |
|
## |
7 |
62800 |
2011_12 |
female |
15 |
“ |
10-19″ |
NA |
White |
|
## |
8 |
56580 |
2009_10 |
female |
79 |
“ |
70+” |
948 |
White |
|
## |
9 |
60833 |
2009_10 |
male |
52 |
“ |
50-59″ |
633 |
White |
|
## |
10 |
67356 |
2011_12 |
female |
49 |
“ |
40-49″ |
NA |
White |
## # … with 69 more variables: Race3 <fct>, Education <fct>, ## # MaritalStatus <fct>, HHIncome <fct>, HHIncomeMid <int>, ## # Poverty <dbl>, HomeRooms <int>, HomeOwn <fct>,
## # Work <fct>, Weight <dbl>, Length <dbl>, HeadCirc <dbl>, ## # Height <dbl>, BMI <dbl>, BMICatUnder20yrs <fct>,
## #BMI_WHO <fct>, Pulse <int>, BPSysAve <int>, ## #BPDiaAve <int>, BPSys1 <int>, BPDia1 <int>,
## #BPSys2 <int>, BPDia2 <int>, BPSys3 <int>, BPDia3 <int>, ## #Testosterone <dbl>, DirectChol <dbl>, TotChol <dbl>, ## #UrineVol1 <int>, UrineFlow1 <dbl>, UrineVol2 <int>,
## #UrineFlow2 <dbl>, Diabetes <fct>, DiabetesAge <int>, ## #HealthGen <fct>, DaysPhysHlthBad <int>,
## #DaysMentHlthBad <int>, LittleInterest <fct>,
## #Depressed <fct>, nPregnancies <int>, nBabies <int>, ## #Age1stBaby <int>, SleepHrsNight <int>,
## #SleepTrouble <fct>, PhysActive <fct>,
## #PhysActiveDays <int>, TVHrsDay <fct>, CompHrsDay <fct>, ## #TVHrsDayChild <int>, CompHrsDayChild <int>,
## #Alcohol12PlusYr <fct>, AlcoholDay <int>,
## #AlcoholYear <int>, SmokeNow <fct>, Smoke100 <fct>, ## #Smoke100n <fct>, SmokeAge <int>, Marijuana <fct>, ## #AgeFirstMarij <int>, RegularMarij <fct>,
## #AgeRegMarij <int>, HardDrugs <fct>, SexEver <fct>, ## #SexAge <int>, SexNumPartnLife <int>,
## #SexNumPartYear <int>, SameSex <fct>, ## #SexOrientation <fct>, PregnantNow <fct>
It might be useful to find the mean pulse rate from a random sample of size 10.
##mean_Pulse
## 1 67.77778
Now suppose you took another random sample of size 10 and found the mean pulse rate for that sample. Repeat this process 100 times. At this point you would basically have a new sample of 100 mean pulse rates. You could assess how this sample is distributed by creating a density plot.
0.100
0.075
density
0.050
0.025
0.000
65707580
means
Figure 6.22: Density Plot of Sample Means When n = 10
##mean_means sd_means ## 173.19368 3.786986
This distribution is a sampling distribution. That is all a sampling distribution is. It is a distribution created from statistics.
𝜇𝑥̄ = 73.8
𝜎𝑥̄ = 4.35
3
Notice the distribution does look a great deal like the distribution of the original random variable. Notice the mean of the sample meansbpm which is almost the same of as the mean of the population. The standard deviation
of the sample means,pbm is about deviation.
1 of the population standard
What does this distribution look like if instead of repeating the experiment 10 times you repeat it 50 times instead?
This density plot of the sampling distribution is displayed in (Figure 6.23).
##mean_means sd_means ## 173.79957 1.987379
0.15
density
0.10
0.05
0.00
67.570.072.575.077.5
means
Figure 6.23: Density Plot of Sample Means When n = 50
Notice this density plot of the sample mean looks approximately symmetrical and could almost be called normal. Notice, the mean of the sample means is
7
73.6 bpm which is approximately what the population mean is. The standard deviation of the sample means is 1.77 bpm which is around 1 of the population standard deviation. What if you keep increasing n? What will the sampling dis- tribution of the sample mean look like? In other words, what does the sampling distribution of 𝑥̄ look like as n gets even larger?
𝜇 = 17.8𝜎 = 5.3
This depends on how the original distribution is distributed. In Example #6.3.1, the random variable was approximately normally distributed. When n was 10, the distribution of the mean looked approximately normal. What if the original distribution wasn’t normal? How big would n have to be? Consider a different variable in the NHANES data frame that isn’t normally distributed such as age when a participant started to smoke cigarettes (SmokeAge). The density plot for the large sample is in (Figure 6.24). The mean for the large sample is 17.8 years and the standard deviation is 5.3 years, sodollars and
dollars approximately.
##mean_SmokeAge sd_SmokeAge ## 117.826625.32666
Now take 100 samples of size 50 individuals from the NHANES Data Frame. Then graph a density plot of SmokeAge. Notice the the sampling distribution
density
0.10
0.05
0.00
204060
SmokeAge
Figure 6.24: Distribution of Age when Started to Smoke
𝜇𝑥̄ =𝜎𝑥̄ =
of the sample means looks fairly normally distributed even though the original random variable was not normally distributed. The mean of the sample mean.
17.8 years and the standard deviation of the sample mean,1.56
years. The mean of the sample mean is the same as the mean of the population, but the standard deviation of the sample mean is much less than the standard deviation of the original data.
0.3
0.2
density
0.1
0.0
12.515.017.520.022.5
means
##mean_means sd_means ## 117.8478 1.463188
then the sample mean, has a mean 𝜇𝑥̄ = 𝜇 and standard deviation of 𝜎𝑥̄ = √
𝜎
Once question is, why is the mean of the sample means the same as the mean of the population? Suppose you have a random variable that has a population mean, 𝜇, and a population standard deviation, 𝜎. If a sample of size n is taken,
. The standard deviation of the sample mean is lower because by taking th𝑛e mean you are averaging out the extreme values, which makes the distribution of the sample mean less spread out.
𝑥̄
𝑥̄
You now know the center and the variability of . You also want to know the shape of the distribution of . You hope it is normal, since you know how to find probabilities using the normal curve. The following theorem tells you the requirement to have 𝑥̄ be normally distributed.
Theorem #6.3.1: Central Limit Theorem.
Suppose a random variable is from any distribution. If a sample of size n is taken, then the sample mean, 𝑥̄, becomes normally distributed as n increases.
𝑥̄
What this says is that no matter what x looks like, would look normal if n is large enough. Now, what size of n is large enough? That depends on how x is distributed in the first place. If the original random variable is normally distributed, then n just needs to be 2 or more data points. If the original random variable is somewhat mound shaped and symmetrical, then n needs to be greater than or equal to 30. Sometimes the sample size can be smaller, but
this is a good general rule to use. The sample size may have to be much larger if the original random variable is really skewed one way or another.
as the standard error of the mean, is actually 𝜎𝑥̄ = √ .Make sure you
𝜎
Now that you know when the sample mean will look like a normal distribu- tion, then you can find the probability related to the sample mean. Remem- ber that the mean of the sample mean is just the mean of the original data (𝜇𝑥̄ = 𝜇), but the standard deviation of the sample mean, 𝜎𝑥̄, also known
=
use this in all calculations. If you are using the z-score,𝑛 the formula when
working with 𝑥 is 𝑧 =
bilities use
𝑥−𝜇𝑥
𝜎𝑥̄
𝑥−𝜎𝜇 . To use R Studio to calculate proba-
√
𝑛
𝑃(𝑥̄ < 𝑎) = 𝑝𝑛𝑜𝑟𝑚(𝑎, 𝜇𝑥̄, 𝜎𝑥̄, 𝑙𝑜𝑤𝑒𝑟.𝑡𝑎𝑖𝑙 = 𝑇 𝑅𝑈𝐸) 𝑃(𝑥̄ > 𝑎) =
𝑝𝑛𝑜𝑟𝑚(𝑎, 𝜇𝑥̄, 𝜎𝑥̄, 𝑙𝑜𝑤𝑒𝑟.𝑡𝑎𝑖𝑙 = 𝐹𝐴𝐿𝑆𝐸).
Example: Finding Probabilities for Sample Means
The birth weight of boy babies of European descent who were delivered at 40 weeks is normally distributed with a mean of 3687.6 g with a standard deviation of 410.5 g (Janssen, Thiessen, Klein, Whitfield, MacNab & Cullis-Kuhl, 2007). Suppose there were nine European descent boy babies born on a given day and the mean birth weight is calculated.
- State the random variable.
Solution:
x = birth weight of boy babies (Note: the random variable is something you measure, and it is not the mean birth weight. Mean weight is calculated.)
- What is the mean of the sample mean?
Solution: 𝜇𝑥̄ = 𝜇 = 3687.4𝑔
- What is the standard deviation of the sample mean?
Solution: 𝜎𝑥̄ = √𝜎 = 41√0.5𝑔 = 136.8𝑔
𝑛9
- What distribution is the sample mean distributed as?
Solution:
Since the original random variable is distributed normally, then the sample mean is distributed normally.
- Find the probability that the mean weight of the nine boy babies born was less than 3500.4 g.
Solution:
To find 𝑃(𝑥̄ < 3500.4) = 0.086. use the R Studio command
pnorm(3500.4,3687.6, 410.5/sqrt(9), lower.tail = TRUE) ## [1] 0.08564231
There is an 8.6% chance that the mean birth weight of the nine boy babies born would be less than 3500.4 g. Since this is more than 5%, this is not unusual.
- Find the probability that the mean weight of the nine babies born was less than 3452.5 g.
Solution:
You are looking for the 𝑃(𝑥̄ < 3452.5).
To find in R Studio, 𝑃(𝑥̄ < 3452.5) = 0.043 use the command
pnorm(3452.5, 3687.4, 410.5/sqrt(9), lower.tail = TRUE)
## [1] 0.04301819
There is a 4.3% chance that the mean birth weight of the nine boy babies born would be less than 3452.5 g. Since this is less than 5% this would be an unusual event. If it actually happened, then you may think there is something unusual about this sample. Maybe some of the nine babies were born as multiples, which brings the mean weight down, or some or all of the babies were not of European descent (in fact the mean weight of South Asian boy babies is 3452.5 g), or some were born before 40 weeks, or the babies were born at high altitudes.
Example: Finding Probabilities for Sample Means
For Americans that smoke, the average age that they started smoking is 17.8 years, with a standard deviation of approximately 1.56 years from the NHANES data. This random variable is not normally distributed, though it is somewhat mound shaped.
- State the random variable.
Solution:
x = age that smoking Americans started to smoke
- Suppose a sample of 35 smoking American’s is taken. Find the probability that the mean age that these 35 smoking Americans started to smoke is more than 21 years.
Solution:
tion of the sample mean is 𝜎𝑥̄ = √= √. You have all the information you
𝜎 1.56
Even though the original random variable is not normally distributed, the sam- ple size is over 30, by the central limit theorem the sample mean will be normally distributed. The mean of the sample mean is 𝜇𝑥̄ = 17.8. The standard devia-
need to use the normal command 𝑛using 3R5 Studio. Without the central limit theorem, you couldn’t use the normal command, and you would not be able to answer this question.
The probability that the mean age that 35 smoking Americans start to smoke is more than 21 years, is the mathematical statement 𝑃(𝑥̄ > 21)
To find 𝑃(𝑥̄ > 21) = 3.42𝑋10−34 using R studio, use the command:
pnorm(21, 17.8, 1.56/sqrt(35), lower.tail=FALSE)
## [1] 3.422499e-34
The probability of a sample mean of 35 smoking Americans being more than 21 years when they smoked for the first time is very small. This is extremely unlikely to happen. If it does, it may make you wonder about the sample. Could the population mean have increased from the 17.8 years as was stated? Could the sample not have been random, and instead have been a group of smoking Americans who had started to smoke much later? These questions, and more, are ones that you would want to ask as a researcher
Homework
- A random variable is not normally distributed, but it is mound shaped. It has a mean of 14 and a standard deviation of 3.
- If you take a sample of size 10, can you say what the shape of the sampling distribution for the sample mean is? Why?
- For a sample of size 10, state the mean of the sample mean and the standard deviation of the sample mean.
- If you take a sample of size 35, can you say what the shape of the distri- bution of the sample mean is? Why?
- For a sample of size 35, state the mean of the sample mean and the standard deviation of the sample mean.
- A random variable is normally distributed. It has a mean of 245 and a standard deviation of 21.
- If you take a sample of size 10, can you say what the shape of the distri- bution for the sample mean is? Why?
- For a sample of size 10, state the mean of the sample mean and the standard deviation of the sample mean.
- For a sample of size 10, find the probability that the sample mean is more than 241.
- If you take a sample of size 35, can you say what the shape of the distri- bution of the sample mean is? Why?
- For a sample of size 35, state the mean of the sample mean and the standard deviation of the sample mean.
- For a sample of size 35, find the probability that the sample mean is more than 241.
- Compare your answers in part c and f. Why is one smaller than the other?
- The mean starting salary for nurses is $67,694 nationally (”Staff nurse -,”
2013). The standard deviation is approximately $10,333. The starting salary is not normally distributed but it is mound shaped. A sample of 42 starting salaries for nurses is taken.
- State the random variable.
- What is the mean of the sample mean?
- What is the standard deviation of the sample mean?
- What is the shape of the sampling distribution of the sample mean? Why?
- Find the probability that the sample mean is more than $75,000.
- Find the probability that the sample mean is less than $60,000.
- If you did find a sample mean of more than $75,000 would you find that unusual? What could you conclude?
- According to the WHO MONICA Project the mean blood pressure for people in China is 128 mmHg with a standard deviation of 23 mmHg (Ku- ulasmaa, Hense & Tolonen, 1998). Blood pressure is normally distributed.
- State the random variable.
- Suppose a sample of size 15 is taken. State the shape of the distribution of the sample mean.
- Suppose a sample of size 15 is taken. State the mean of the sample mean.
- Suppose a sample of size 15 is taken. State the standard deviation of the sample mean.
- Suppose a sample of size 15 is taken. Find the probability that the sample mean blood pressure is more than 135 mmHg.
- Would it be unusual to find a sample mean of 15 people in China of more than 135 mmHg? Why or why not?
- If you did find a sample mean for 15 people in China to be more than 135 mmHg, what might you conclude?
- The size of fish is very important to commercial fishing. A study conducted in 2012 found the length of Atlantic cod caught in nets in Karlskrona to have a mean of 49.9 cm and a standard deviation of 3.74 cm (Ovegard, Berndt & Lunneryd, 2012). The length of fish is normally distributed. A sample of 15 fish is taken.
- State the random variable.
- Find the mean of the sample mean.
- Find the standard deviation of the sample mean
- What is the shape of the distribution of the sample mean? Why?
- Find the probability that the sample mean length of the Atlantic cod is less than 52 cm.
- Find the probability that the sample mean length of the Atlantic cod is more than 74 cm.
- If you found sample mean length for Atlantic cod to be more than 74 cm, what could you conclude?
- The mean cholesterol levels of women age 45-59 in Ghana, Nigeria, and Seychelles is 5.1 mmol/l and the standard deviation is 1.0 mmol/l (Lawes,
Hoorn, Law & Rodgers, 2004). Assume that cholesterol levels are normally distributed.
- State the random variable.
- Find the probability that a woman age 45-59 in Ghana has a cholesterol level above 6.2 mmol/l (considered a high level).
- Suppose doctors decide to test the woman’s cholesterol level again and average the two values. Find the probability that this woman’s mean cholesterol level for the two tests is above 6.2 mmol/l.
- Suppose doctors being very conservative decide to test the woman’s choles- terol level a third time and average the three values. Find the probability that this woman’s mean cholesterol level for the three tests is above 6.2 mmol/l.
- If the sample mean cholesterol level for this woman after three tests is above 6.2 mmol/l, what could you conclude?
- In the United States, males between the ages of 40 and 49 eat on average
103.1 g of fat every day with a standard deviation of 4.32 g (”What we eat,” 2012). The amount of fat a person eats is not normally distributed but it is relatively mound shaped.
- State the random variable.
- Find the probability that a sample mean amount of daily fat intake for 35 men age 40-59 in the U.S. is more than 100 g.
- Find the probability that a sample mean amount of daily fat intake for 35 men age 40-59 in the U.S. is less than 93 g.
- If you found a sample mean amount of daily fat intake for 35 men age 40-59 in the U.S. less than 93 g, what would you conclude?
- A dishwasher has a mean life of 12 years with an estimated standard deviation of 1.25 years (”Appliance life expectancy,” 2013). The life of a dishwasher is normally distributed. Suppose you are a manufacturer and you take a sample of 10 dishwashers that you made.
- State the random variable.
- Find the mean of the sample mean.
- Find the standard deviation of the sample mean.
- What is the shape of the sampling distribution of the sample mean? Why?
- Find the probability that the sample mean of the dishwashers is less than 6 years.
- If you found the sample mean life of the 10 dishwashers to be less than 6 years, would you think that you have a problem with the manufacturing process? Why or why not?
Data Sources:
Annual maximums of daily rainfall in Sydney. (2013, September 25). Retrieved from http://www.statsci.org/data/oz/sydrain.html
Appliance life expectancy. (2013, November 8). Retrieved from http://www. mrappliance.com/expert/life-guide/
Bhat, R., & Kushtagi, P. (2006). A re-look at the duration of human pregnancy. Singapore Med J., 47 (12), 1044-8. Retrieved from http://www.ncbi.nlm.nih. gov/pubmed/17139400
College Board, SAT. (2012). Total group profile report. Retrieved from web- site: http://media.collegeboard.com/digitalServices/pdf/research/TotalGroup- 2012.pdf
Janssen, P. A., Thiessen, P., Klein, M. C., Whitfield, M. F., MacNab, Y. C., & Cullis-Kuhl, S. C. (2007). Standards for the measurement of birth weight, length and head circumference at term in neonates of european, chinese and south asian ancestry. Open Medicine, 1(2), e74-e88. Retrieved from http:// www.ncbi.nlm.nih.gov/pmc/articles/PMC2802014/
Kiama blowhole eruptions. (2013, September 25). Retrieved from http://www. statsci.org/data/oz/kiama.html
Kuulasmaa, K., Hense, H., & Tolonen, H. World Health Organiza- tion (WHO), WHO Monica Project. (1998). Quality assessment of data on blood pressure in the who monica project (ISSN 2242-1246). Retrieved from WHO MONICA Project e-publications website: http:
//www.thl.fi/publications/monica/bp/bpqa.htm
Lawes, C., Hoorn, S., Law, M., & Rodgers, A. (2004). High cholesterol. In M. Ezzati, A. Lopez, A. Rodgers & C. Murray (Eds.), Comparative Quantification of Health Risks (1 ed., Vol. 1, pp. 391-496). Retrieved from http://www.who. int/publications/cra/chapters/volume1/0391-0496.pdf
Ovegard, M., Berndt, K., & Lunneryd, S. (2012). Condition indices of Atlantic cod (gadus morhua) biased by capturing method. ICES Journal of Marine Science, doi: 10.1093/icesjms/fss145
Staff nurse – RN salary. (2013, November 08). Retrieved from http://www1. salary.com/Staff-Nurse-RN-salary.html
US Department of Agriculture, Agricultural Research Service. (2012). What we eat in America. Retrieved from website: http://www.ars.usda.gov/Services/ docs.htm?docid=18349
